关于DAO数据访问对象设计其实是关于GoFrame框架工程化实践中比较重要一块设计。
DAO设计结合GoFrame的ORM组件性能和易用性都很强,可以极大提高开发和维护效率。看完本章节内容之后,小伙伴们应该能够理解并体会到使用DAO数据库访问对象设计的优点。
我每年都会来回重新审视这篇文章,看看是否可以删除一些地方。可是每次都倍感失望,因为这篇文章对当今现状仍旧适用。并且今年,我还新增了内容。
一、现有ORM使用示例
1、需要定义模型
 用户基础表(仅作演示,真实的表有数十个字段)
用户基础表(仅作演示,真实的表有数十个字段)
 医生信息表(仅作演示,真实的表有上百个字段)
医生信息表(仅作演示,真实的表有上百个字段)
2、GRPC接口实现示例
一个简单的GRPC查询信息接口。
 一个简单的
一个简单的GRPC数据查询接口
二、现有痛点描述
1、必须要定义tag关联表结构与struct属性,无法做到自动映射
表字段与实体对象属性名称之间原本就有一定的关联规则,没有必要定义和维护大量的tag定义。
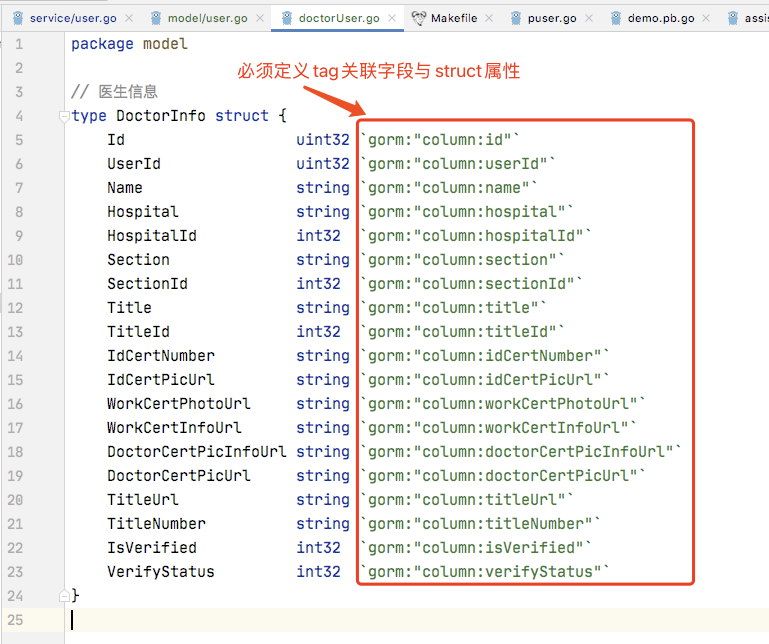
大量非必要的tag定义,用于指定数据表字段到实体对象属性映射
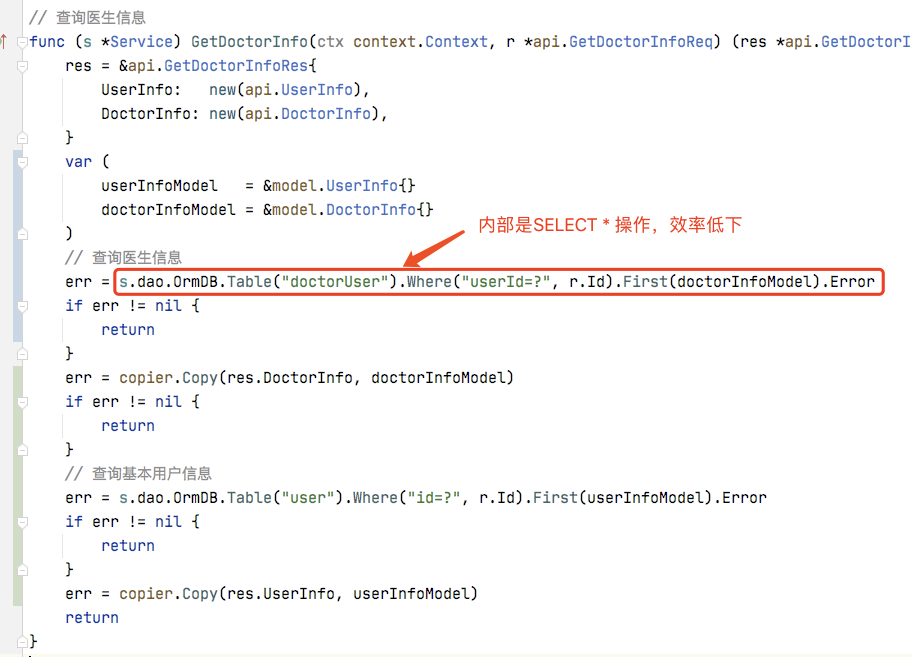
2、不支持通过返回对象指定需要查询的字段
无法通过返回的对象数据结构指定查询字段,要么只能SELECT * ,要么只能通过额外的方法手动录入查询字段,效率很低下。
3、无法对输入对象属性名称进行自动字段过滤
定义了输入与输出数据结构,输出的数据结构已经包含我们需要查询的字段名称。开发者输入定义的返回对象,期望在查询的时候仅查询我需要的字段名称,多余的属性则不会执行查询,自动过滤掉。
4、需要创建中间查询结果对象执行赋值转换
查询结果不支持struct智能转换,需要额外定义一个中间model模型,再通过其他工具进行复制,效率低。

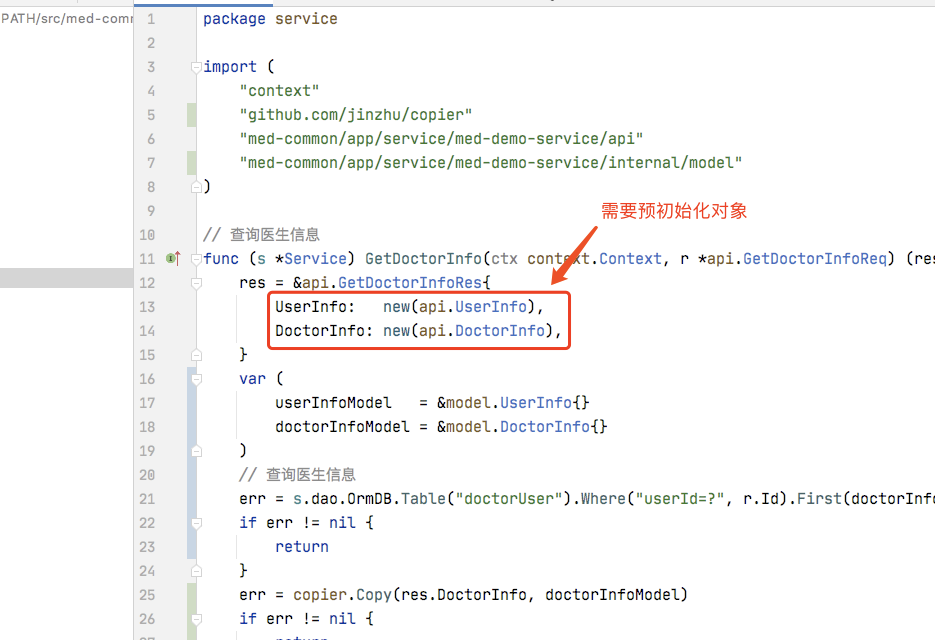
5、需要提前初始化返回对象,不管有无查询到数据
这种方式不仅不优雅,对性能也有影响,还对GC不太友好。期望查询到数据时再自动创建返回对象,没有查询到数据时什么都不要做。
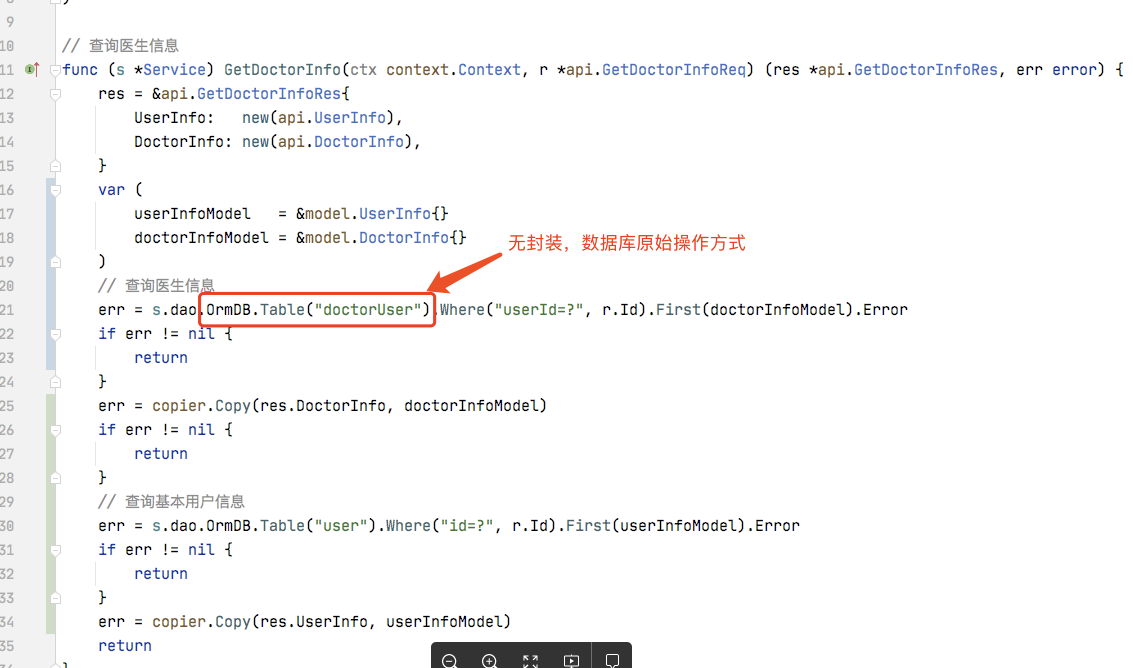
6、项目通篇使用底层裸DB对象操作,没有对象封装操作
大部分的Golang初学者似乎都倾向于使用一个全局的DB对象,在查询的时候通过DB对象生成特定表的Model对象再执行CURD操作,这是一种面向过程的使用方式。这种方式并没有代码分层的设计可言,使得数据操作和业务逻辑高度耦合。
7、随处可见的字符串硬编码,如表名和字段的硬编码
举个例子,userId这个字段假如一不小心写成了UserId或者userid,测试的时候如果没有完全覆盖到,在一定的条件下才触发查询操作,是不是会造成新的一场事故呢?

大量的字符串硬编码
8、底层ORM引起太多的指针属性定义
指针属性对象为业务逻辑处理埋下隐患,开发者在代码逻辑中需要在指针与属性之间来回切换,特别是一些基础类型往往需要通过重新取值的方式传递参数。如果输入参数是interface{}类型,那么更容易引起BUG。
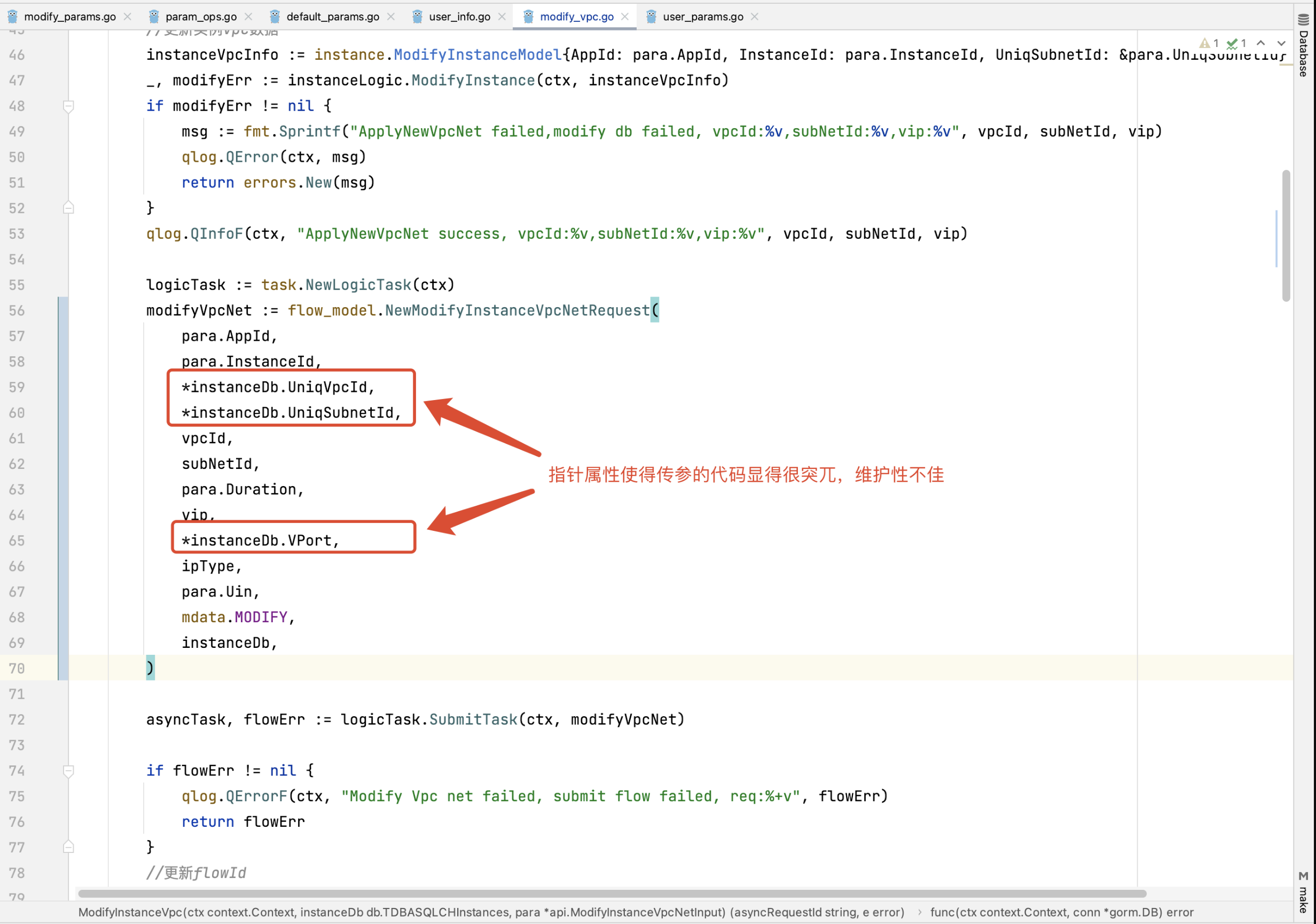
BUG示例,指针属性使用不当,引起地址比较逻辑错误。
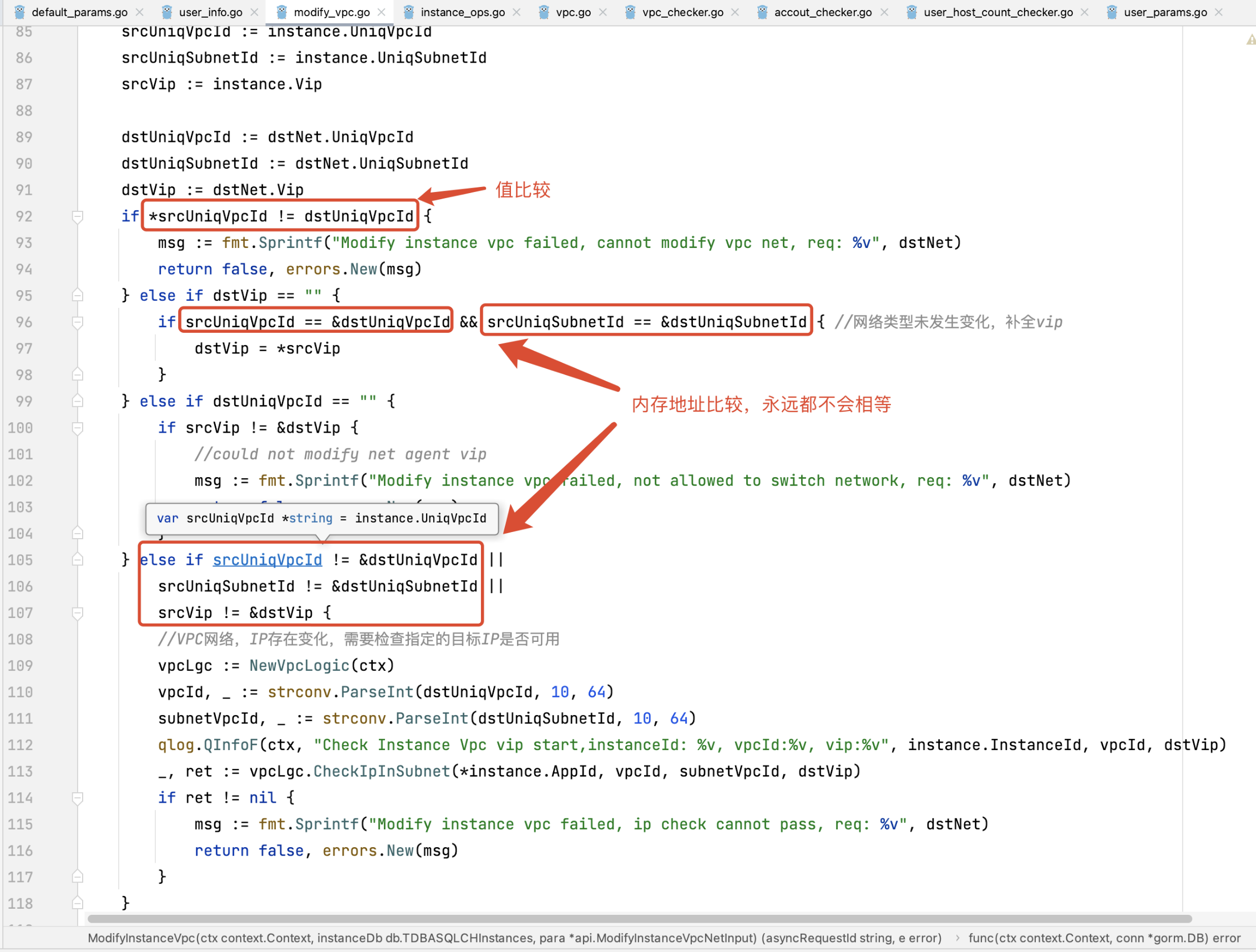
同时也影响了业务模型结构体定义设计,对开发者造成了错误习惯引导(上层业务模型的指针属性往往是为了迎合底层数据表实体对象,方便数据传递)。
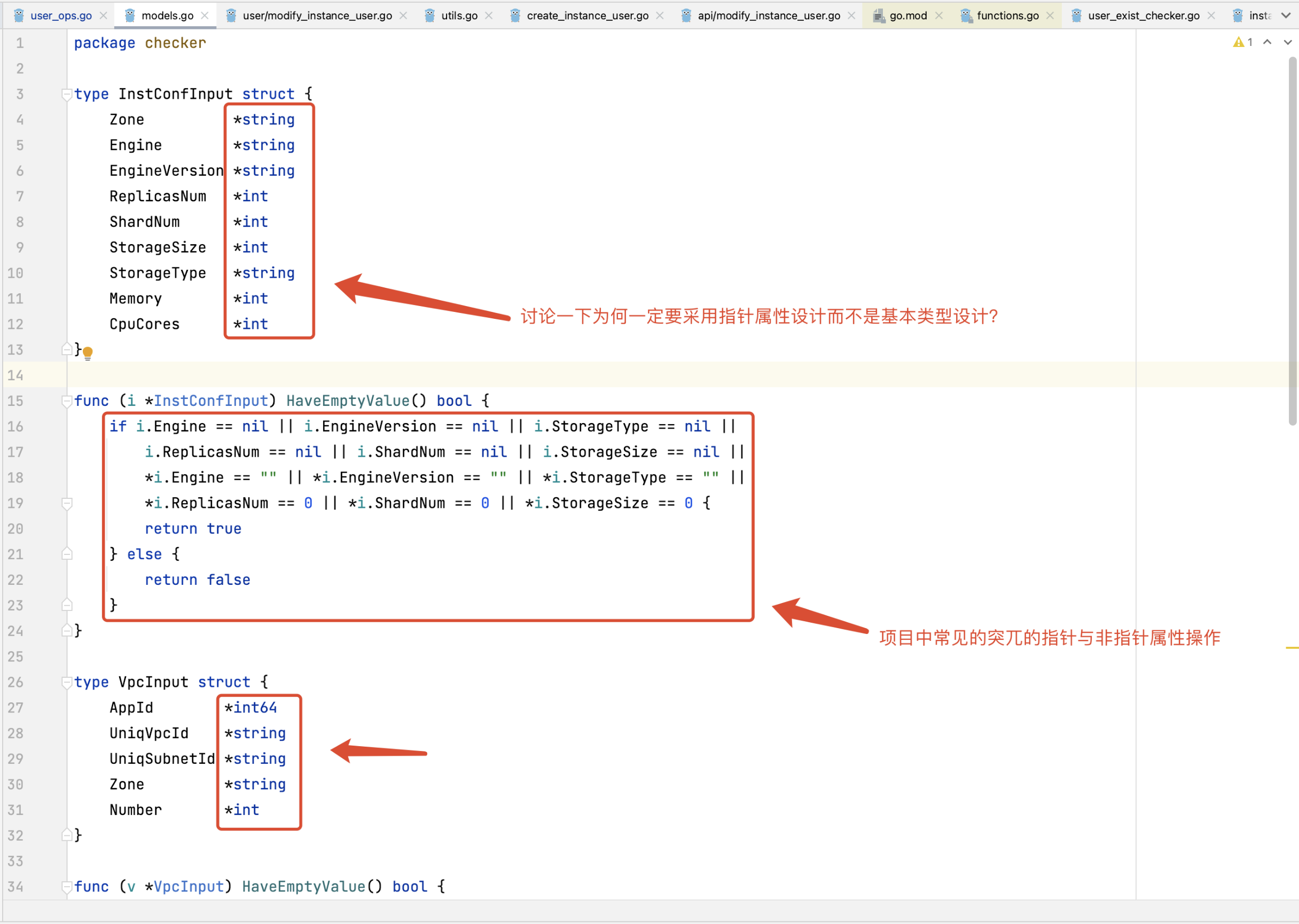
值得注意一个常见错误,就是将底层数据实体模型当做顶层业务模型使用。特别是在底层数据实体对象使用指针属性的场景下,该问题十分明显。
9、可观测性的支持:Tracing、Metrics、Logging
数据库ORM作为业务项目最关键核心的组件,可观测性的支持至关重要。
10、数据集合与代码数据实体结构不一致
当通过人工维护数据实体结构时,数据集合与代码数据实体结构往往会出现不一致的风险,开发和维护成本高。
三、改进方案设计
1、查询结果对象无需特殊标签定义,全自动关联映射
2、支持根据指定对象自动识别查询字段,而不是全部SELECT *
3、支持根据指定对象自动过滤不存在的字段内容
4、使用DAO对象封装代码设计,通过对象方式操作数据表
5、DAO对象将关联的表名及字段名进行封装,避免字符串硬编码
6、无需提前定义实体对象接受返回结果,无需创建中间实体对象用于接口返回对象的赋值转换
7、查询结果对象无需提前初始化,查询到数据时才会自动创建
8、内置支持OpenTelemetry标准,实现可观测性,极大提高维护效率、降低成本
9、支持SQL日志输出能力,支持开关功能
10、数据模型、数据操作、业务逻辑解耦,支持Dao及Model代码工具化自动生成,保证数据集合与代码数据结构一致,提高开发效率,便于规范落地
11、等等。

采用DAO设计改进后的代码示例
24 Comments
lilo
支持
ayamzh
从使用者角度给强哥提些建议,
service层代码 通过dao.table("xxx").where().find(),实际是service层在维护数据访问的逻辑,dao只是个驱动而已。建议service层只做原始数据的业务逻辑的加工,把sql的维护放在dao层。 类似于:userservice.getuser() { userdao.FetchByID(UID) } userdao.fetchByID(uid uint64) *Userstruct { return db.where("uid = ?").find.bindtostruct() }这样有两个好处,
service层不用关心数据来自db还是缓存,可以在dao层做缓存控制。2是userstuct可以在包一个entity层 相当于entity对象里套着userstruct(数据表结构体的映射结构体),因为很多业务场景往往要对原始数据做进一步加工,这层加工可以在entity层做。我以前做的php和go项目都延用这套升级。相当于ctrl做输入输出的校验,业务流程。service封装业务逻辑力度尽量细,dao做数据数据访问层(sql语句)和缓存策略管理,entity做数据库对象的映射,同时支持重载底层字段。郭强
我也算是一路踩坑过来的苦逼码农,你这个建议其实是一个经典问题,在这篇文章中有提及到:代码分层设计
dao与service的职责边界维护其实并不容易(有时比较模糊),对于有经验的开发者来说往往并不是什么问题,问题在于团队架构是有层级的,要保证团队的每个成员都能编写好边界清晰的代码并不容易(往往很难,所以才会有技术债务和重构这一概念)。往往这个时候团队管理者需要依靠简单的逻辑去制定规范,文章中给的建议便是如此。你的那个
FetchByID的例子放dao可以(dao设计有这样的扩展能力,其实我们也有很多dao的自定义数据接口),是否由dao来控制缓存却不能一概而论,因为dao是共用的,这得看业务场景,否则其他的开发者调用了你的接口得到一个意想不到的缓存值可能会是一个问题。好的代码管理是不需要别人深入去看你的代码逻辑就知道有没有带额外特性,如果团队明确规定dao就只是数据库CURD逻辑,而是否需要缓存由service封装具体的业务场景的逻辑来决定,设计简单便不易出错。service调用dao的链式操作来实现数据访问确实是将dao的职责给减轻了,却并没有限制dao的数据封装和扩展能力。写代码是一门手艺,拿捏得当却是一门艺术。
ayamzh
明白了。刚我看了下gf-demo源码,model和dao外面都有包一层,我光看文档了没看代码~有需要的可以在这两层做我说得工作,另外强哥说的dao是公用的,走缓存和不走缓存的find方法如果都有需要,那就应该是2个function,比如叫find 和 fetch,因为即使放到service层如果两种数据来源都需要。也是要显式区分的。因为无论来源是缓存还是数据库,对业务层来说都是数据,感觉上归到dao层以组合的方式来实现,更通顺一些
刘羽禅
在dao的函数的输入参数里,加一个isCache字段,
如果service层需要从缓存里获取数据,这个字段就是1 或者 true,
如果不需要从缓存里取数据,就传递0,或者false
这样是否可行呢?
ayamzh
跟我们以前的一样我们以前是php,在daobase里组合一个cachetrait,提供2套function一套是withcache的,底层就是你说的这样用函数参数控制是否缓存。
郭强
刘羽禅 ayamzh 有个
Cache链式操作方法控制缓存,具体可以参考章节 ORM链式操作-查询缓存 。关于放dao还是service,我之前的回复也有建议,可作参考。刘羽禅
好的 谢谢 您的文档 写的很详细 很棒
刘羽禅
嗯嗯 使用__Call( )函数,实现的
不使用缓存是 getUser($uid)
使用缓存是 getUserFrom($uid)
yzl
dao这个设计太棒了。
想请教下:
见很多地方,查询、添加、修改的请求参数是在
dao外层写的,但看gf-demos是在model外层写的。请问,应该在
dao,还是model写更合理呢?示例如下:
type UserApiSignUpReq struct { Passport string `v:"required|length:6,16#账号不能为空|账号长度应当在:min到:max之间"` Password string `v:"required|length:6,16#请输入确认密码|密码长度应当在:min到:max之间"` Password2 string `v:"required|length:6,16|same:Password#密码不能为空|密码长度应当在:min到:max之间|两次密码输入不相等"` Nickname string }郭强
CRUD可以在dao中写,也可以在service中写,model只是数据结构定义。sanrentai
关于 dao 包和 do 包的探讨
在实际使用中每个表都会在 dao/internal 包中生成 一个go 文件,除了 有各自的 column 外其他部分都相同,而这个 column 目前来看是为了解决查询字段的硬编码问题,那么是否可以换一种做法呢?
取消column结构,并为do struct 的字段添加 column tag 用来映射数据库字段,这样在查询是可以通过Where传入do对象来查询,同样避免查询时字段硬编码问题
type User struct { g.Meta `orm:"table:sys_user, do:true"` Id interface{} `column:"id"` // ID Name interface{} `column:"name"` // 姓名 }在查询时orm框架会查询表的字段,导致首次查询时间较长,entity包是否考虑加上orm tag,这样在查询直接通过该tag值来生成查询的字段,生成的字段最好使用 表名tag.字段tag
是否可以利用golang的组合模式,在 internal 包中定义一个 Dao interface 包含通用的方法,再定义一个 BaseDao 实现这个方法 ,并创建一个 func NewDao(table string,group ...string) Dao ,这样可以大量减少代码量.
package internal import ( "context" "github.com/gogf/gf/v2/database/gdb" "github.com/gogf/gf/v2/frame/g" ) type Dao interface { DB() gdb.DB Table() string Group() string Ctx(context.Context) *gdb.Model Transaction(context.Context, func(context.Context, *gdb.TX) error) error } type BaseDao struct { table string group string } func NewDao(table string, group ...string) Dao { if len(group) > 0 { return &BaseDao{group: group[0], table: table} } else { return &BaseDao{group: "default", table: table} } } func (dao *BaseDao) DB() gdb.DB { return g.DB(dao.group) } func (dao *BaseDao) Table() string { return dao.table } func (dao *BaseDao) Group() string { return dao.group } func (dao *BaseDao) Ctx(ctx context.Context) *gdb.Model { return dao.DB().Model(dao.table).Safe().Ctx(ctx) } func (dao *BaseDao) Transaction(ctx context.Context, f func(ctx context.Context, tx *gdb.TX) error) (err error) { return dao.Ctx(ctx).Transaction(ctx, f) }package dao import "mydemo/internal/service/internal/dao/internal" type userDao struct { internal.Dao } var ( User = userDao{ internal.NewDao("sys_user", "default"), } )郭强
sanrentai 你好,感谢建议,看得出来你也在认真地思考设计和改进方案。这里我回复一下:
Columns设计解决的问题确实为了避免硬编码,虽然DO能解决大部分硬编码的场景,但是Columns也有存在的必要。Columns不存在的前提下,通过接口化设计DAO的建议非常棒。issue,后面可以改进。sanrentai
如果Columns 必须存在,是否考虑将它放到 dao/user.go 中来定义呢
郭强
你好,在
entity中有定义,不过do包的对象中似乎没有,可以改进在do上增加结构体标签避免数据表结构的SQL查询。可以考虑给cli工具提供PR。Roc.Chang
一款面向国人开发的框架,并且付出那么多的精力去维护,很值得让人尊敬!!非常感谢~~
perfect
gorm 也有了差不多的实现
https://github.com/go-gorm/gen#gormgen
刘海峰
试了一下,gen dao识别不到pgsql的varchar[]数组,但是可以识别到int4[]数组,这个是等更新,还是有其他解决方式呀
刘海峰
试了下pgsql的json也不支持,都要自己手动转一下了,难受o(╥﹏╥)o
郭强
建议提个
PR,很简单,参考现有driver实现:https://github.com/gogf/gf/blob/5f146720fef809a13b2af6105c00bc16a19bf894/contrib/drivers/pgsql/pgsql.go#L164摩登土狗
1/2/4 目前的 gorm 好像也没这么不堪:
1 gorm 大多数情况下可以不手动写 clolumn tag 的
2 支持 select 具体字段或者使用 pluck 方法
4 取值映射到结构体的时候也是支持自定义一些和数据库定义不同的中间结构体的
只是阅读过程中结合自己的认知得出的一点看法。
摩登土狗
gorm 到处都要硬编码确实是让人很抓狂的一个点
runrui.wang
golang 写 CURD 是真的没有 ASP.NET Core来的方便,只要实体和表能对应上,都不用写代码。 go要手动处理null的问题,要处理时间的问题,入库和输出实体大小写问题。感觉go语言这方面真应该改进
阿姆斯壮
目前的设计是:根据数据库表结构 ----》 gen dao ----》 生成 dao 相关代码。
这样就需要每次手动维护数据库的迁移,再生成代码。是否考虑将 golang-migrate 类似的迁移管理工具集成进来? 在 manifest\migrations 中去维护迁移的sql脚本呢?